A union offers the possibility to mix several data sets. The source data does not have to have identical attributes (column names). If identical attributes are present, the same column is written to.
An example:
Data Set 1:
| dog name | breed | color |
|---|---|---|
| Waldo | dachshund | brown |
| Wasti | hybrid | colorful |
| Bello | poodle | black |
Data Set 2:
| cat name | breed | favorite food |
|---|---|---|
| Fluffy | persian cat | fish |
| Hugo | maine-coon-cat | schnitzel |
| Mason | sibirian cat | shoes |
These two tables have a common attribute(breed). The union creates the following table with 6 records (rows) and 5 attributes (column names):
| dog name | breed | color | cat name | favorite food |
|---|---|---|---|---|
| Waldo | dachshund | brown | undefined | undefined |
| Wasti | hybrid | colorful | undefined | undefined |
| Bello | poodle | black | undefined | undefined |
| undefined | persian cat | undefined | Fluffy | fish |
| undefined | maine-coon-cat | undefined | Hugo | schnitzel |
| undefined | sibirian cat | undefined | Mason | shoes |
Create a Union
A new union is created, as with all operations, by dragging the icon from the side menu bar onto the graphical flow editor.
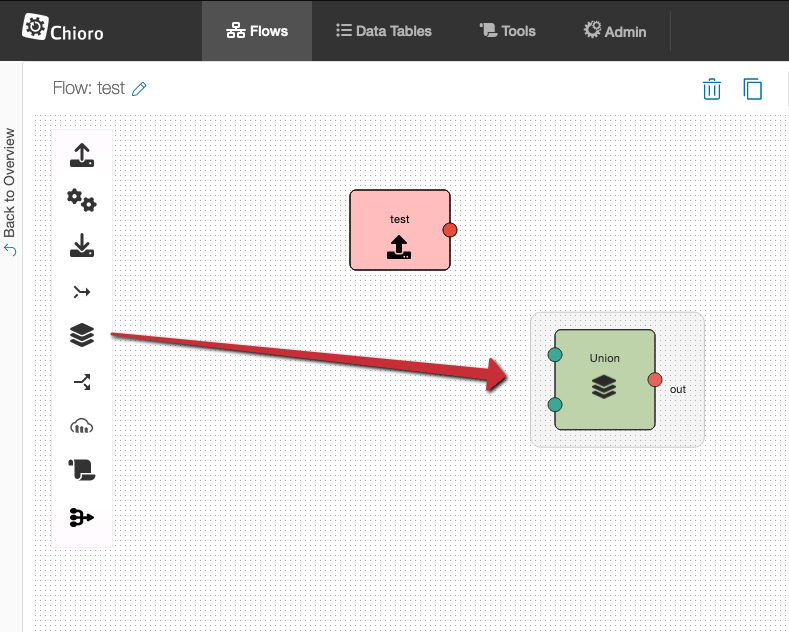
At the beginning a union has 2 inputs. If these two are connected, a further input automatically appears which can be connected.
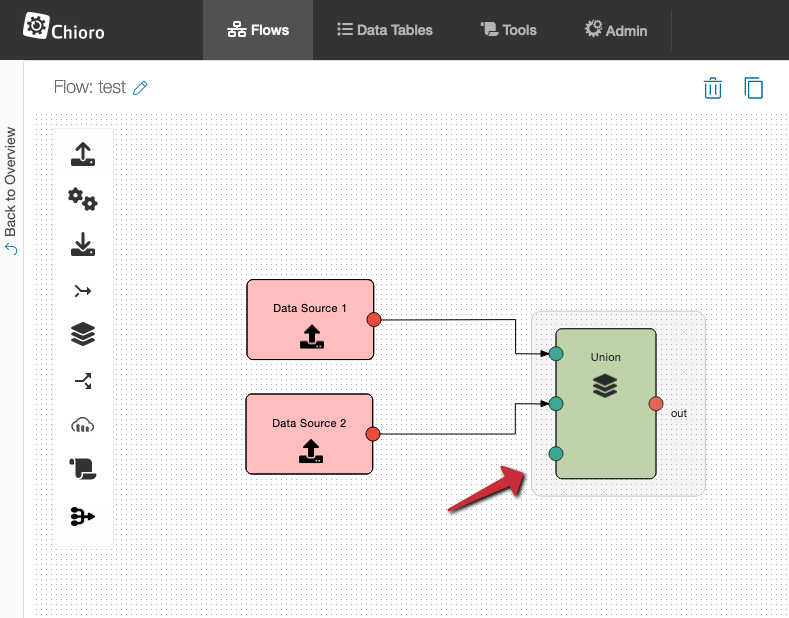
This automatic expansion continues up to a maximum of 10 inputs. Inputs can be removed by deleting the connection.
Configuration, start and evaluation
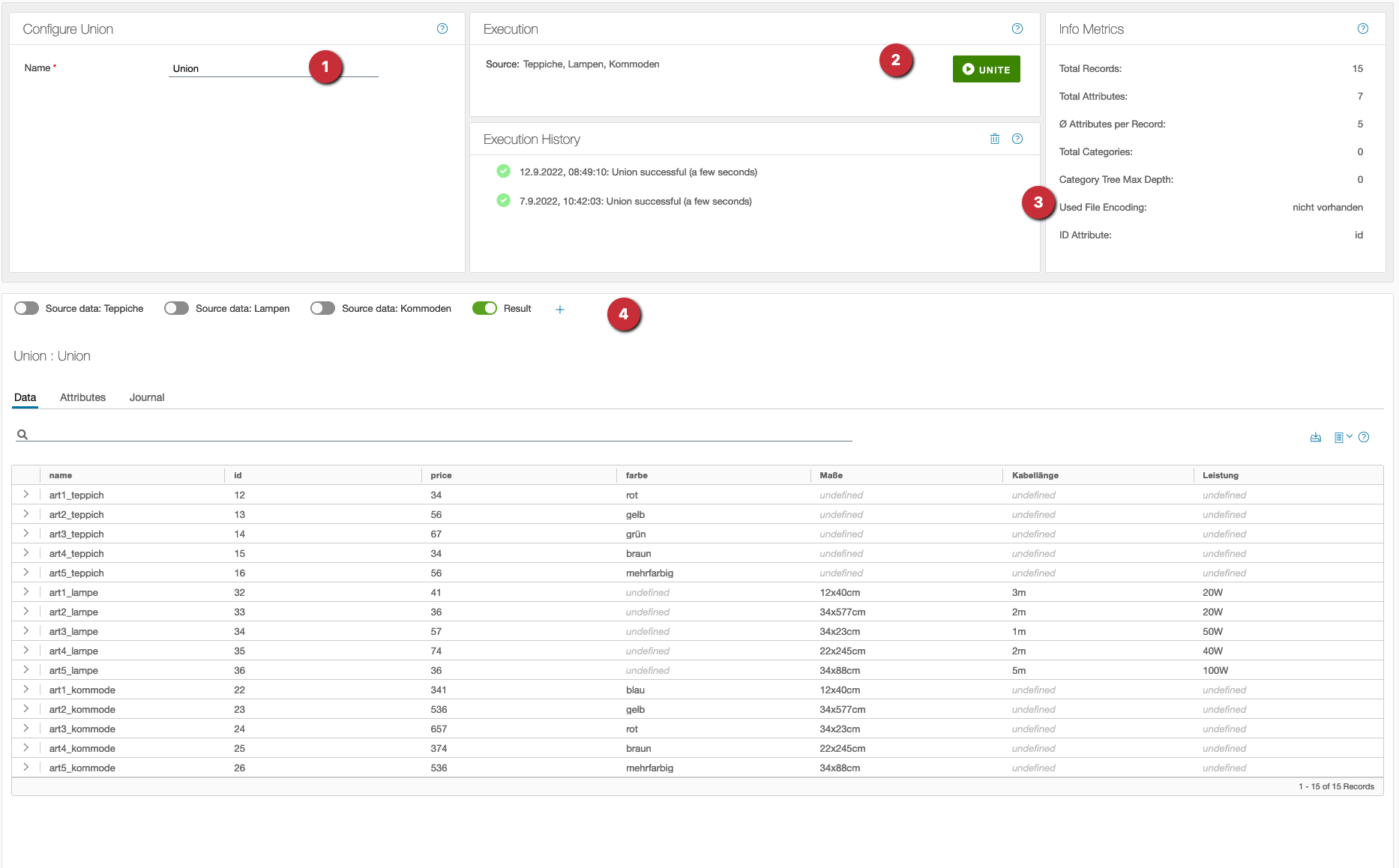
- Apart from a (meaningful) name nothing can and must be configured.
- The execution is started with UNITE.
- History and metrics are available after the execution.
- The result can be examined in the table view below.
Afterwards the data is available at the output for further flow operations.