Eine Datenquelle bindet externe Daten an Chioro an. Sie liest oder empfängt die Daten von einem externen Endpunkt und konvertiert sie bei der Ausführung in das interne Format von Chioro.
Datenquellen stellen quasi die Startpunkte eines Flows dar. Jeder Flow benötigt folglich mindestens eine Datenquelle.
Die Konfiguration einer Datenquelle umfasst drei wesentliche Aspekte:
- In welchem Format liegen die Daten vor?
- Mit welchen Zeichensatz sollen die Daten gelesen werden?
- Woher kommen die Daten?
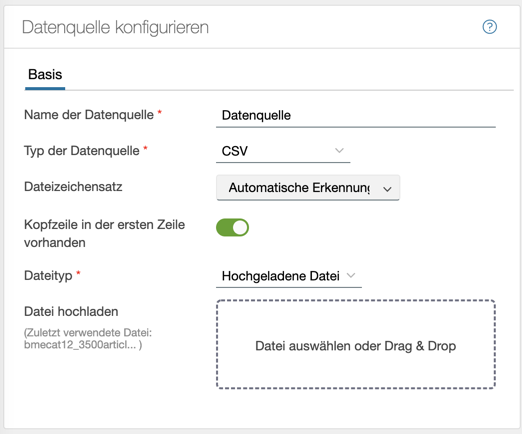
Typ der Datenquelle
Aktuell gibt es vier grundlegende Möglichkeiten, Produktdaten in Chioro zu importieren:
- Hochladen einer Datei über den Browser. Haupsächlich gedacht zum testen und spielen.
- Remote Datei. Direkter (Pull-)Zugriff auf Daten über eine Reihe von Protokollen. Unter anderem FTP, SFTP, S3 (verschiedene Anbieter) und Microsoft Azure. Näheres siehe unten.
- API Push. Über die Push API ist es möglich, Daten aktiv an eine Chioro Datenquelle zu senden. Näheres siehe unten.
- Operation Über die Operation ist es möglich, das Ergebnis einer Operation aus einem anderen Flow in die Datenquelle zu importieren und es als Quelle zu benutzen
Datei hochladen
Ist dieser Typ ausgewählt, erscheint eine graue Fläche in die eine Datei per Drag&Drop gezogen werden kann. Alternativ öffnet ein Klick auf die Fläche einen Dateiauswahldialog.
- Während des Hochladens der Datei bitte nicht zu einer anderen Seite navigieren, den Browser schließen oder die Seite aktualisieren. Andernfalls muss der Datei-Upload erneut durchgeführt werden.
- Bitte beachten sie ausserdem, dass das Hochladen nur für kleinere Dateien bis ca. 100 MB sinnvoll ist.
Remote Datei
Für den direkten Zugriff auf eine Remote Datei werden mehrere, zusätzliche Einstellungen getroffen:
- Im Feld Storage wird ein Endpunkt ausgewählt. Ein Storage wird im Admin-Menü konfiguriert, d.h. dort werden z.B. Zugangsdaten für ein S3-Bucket hinterlegt. Der dort vergebene Name erscheint hier zur Auswahl.
- Das Feld Pfad gibt dann den Pfad der zu verwendenden Datei relativ zu diesem Endpunkt an.
Es muss mindestens der Root-Path eingetragen werden, also ein einzelner Slash: /
Liegt die Datei in einem Unterordner könnte der Pfad beispielhaft so aussehen: /Merchant/Unterordner/Eingang - In Dateiname kann die Datei direkt angegeben werden, z.B. Kundendaten.csv oder es wird eine Wildcard verwendet. Werden bei der Auswertung der Wildcard mehrere passende Dateien ermittelt, nimmt Chioro die Neuste.
Ein Beispiel, hier wird * verwendet um beliebige Zeichen zu repräsentieren:
Folgende Dateien liegen in einem Ordner:
| Dateiname | Änderungsdatum |
|---|---|
| daten1.csv | 1.1.2020 10:00 |
| daten2.csv | 1.1.2020 10:30 |
| daten3.csv | 1.1.2020 10:45 |
| daten1.json | 1.1.2020 11:30 |
| daten2.json | 1.1.2020 11:00 |
| daten1.xml | 1.1.2020 12:30 |
Beispiele für die ermittelte und zum Importieren vorgesehene Datei:
| Wildcard | Ermittelte Datei | Kommentar |
|---|---|---|
| *.csv | daten3.csv | Die neuste Datei mit der Endung .csv |
| *2.csv | daten2.csv | Die einzige Datei auf die *2.csv zutrifft |
| * | daten1.xml | Die jüngste/neuste aller Dateien |
| daten1.* | daten1.xml | Die neuste Datei die mit daten1 beginnt |
Endpunkte stellen eine Art “Basis URL” dar. Da diese meist vertrauliche Informationen wie Passwörter oder API Schlüssel enthalten, erfolgt deren Konfiguration im Admin Bereich. Hierfür sind entsprechende Admin Rechte erforderlich. Bitte wenden Sie sich an Ihren Chioro Administrator oder an unseren Support, falls Sie keine entsprechenen Rechte besitzen.
API Push
Ist dieser Typ ausgewählt, wird eine für diese Datenquelle spezifische URL generiert und angezeigt. Über diese URL können Daten per HTTP PUSH an die Datenquelle gesendet werden.
Datensätze, welche an die Push API gesendet werden, werden zunächst in der Datenquelle gepuffert. Erst wenn eine Ready-For-Processing Nachricht geschickt wird, wird die Datenquelle “aktiv”. D.h. erst dann werden die Daten analysiert und erst dann stehen die Daten nachfolgenden Operationen zur Verfügung. Ausserdem wird die Datenquelle erst dann von einem Auslöser als “bereit mit neuen Daten” erkannt.
Eine Push Datenquelle kann aber durch manuellen Start des Imports (über den “Importieren” Button) sofort aktiviert werden. Ggf. liegen dann aber nur partielle Daten an.
Mehr zur Verwendung in einer Datenquelle findet sich weiter unten bei Externe Datenquellen.
Operation
Über diese Option ist es möglich das Ergebnis einer anderen Operation aus einem anderen Flow auszuwählen und es als Quelle zu nutzen.
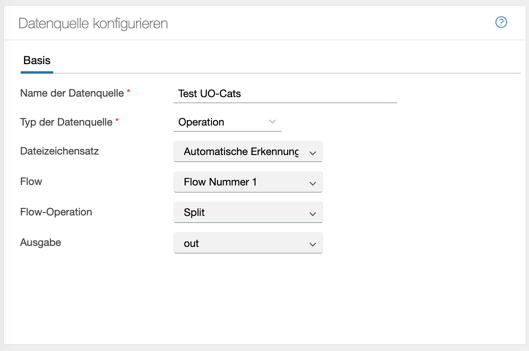
In diesem Beispiel ist als Datenquelle der Output eines Split namens “out” aus dem “Flow Nummer 1” importiert. Diese Daten können dann weitergenutzt werden, für etwaige Operationen.
Es besteht aber auch die Möglichkeit, eine andere Operation als Quelle zu nutzen:
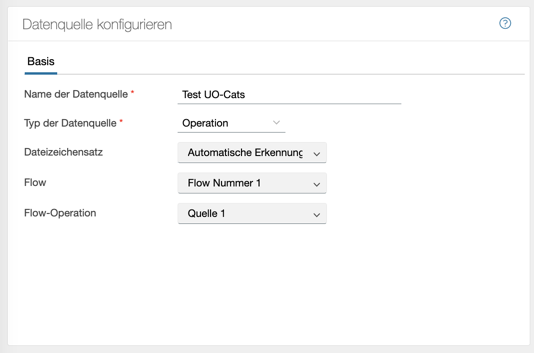
Hier ist zu sehen, dass auch eine Quelle eines anderen Flows als Quelle für den eigenen Flow eingestellt werden kann. Alle Operationen außer “Datenziele” können als Quelle genutzt werden.
Datenformate
Zurzeit unterstützt Chioro folgende Import-Formate:
- JSON
- Excel (xlsx)
- CSV
- BMEcat v1.2
- BMEcat 2005
- Datenformate zur Anbindung an die commercetools Produktdaten API
- sowie ggf. anwenderspezifische Formate, sofern diese aktiviert sind
Für weitere, z.B. anwenderspezifisch Datenformate wenden Sie sich bitte an unseren Support.
Externe Datenquellen
Diese Art Datenquelle ermöglicht die Integration von externen Systemen. Um diese Quellen nutzen zu können, muss ein externes Programm in der Lage sein, Datensätze in einem bestimmten Format (JSON) über “REST over HTTP” zu übertragen. Im Gegensatz zum Rest der Chioro API, ist für den Zugriff auf diesen Endpunkt ein spezieller API-Schlüssel erforderlich, der als Teil der HTTP-Header übermittelt werden muss. Im Weiteren wird das Header- und Body-Format im Detail beschrieben.
Header
Um ein API Token zu erstellen, gehen Sie bitte in den Admin-Bereich und erstellen Sie eine Konfiguration vom Typ API Key. Bitte beachten Sie
den API-Schlüssel, der sofort nach der Erstellung angezeigt wird. Dieser Schlüssel wird nur einmal angezeigt und kann danach nicht mehr eingesehen werden.
Um die externe API zu nutzen, verwenden Sie bitte diesen Schlüssel im HTTP-Header im folgenden Format (ersetzen Sie den <<API_TOKEN>> unten):
Authorization: Token <<API_TOKEN>>
Body
Der Text der Anfrage muss wie folgt formatiert werden:
{
"executionId": "eine ID, nicht erforderlich, aber empfohlen",
"operation": "eine der Optionen CLEAR, APPEND oder READY_TO_PROCESS. Beschreibung unten",
"data" : [{}, {}, {}, ...]
}
Bitte beachten Sie, dass nur die Anweisung “POST” unterstützt wird.
Operation
- CLEAR: die Datenquelle wird neu generiert und geleert. Alle vorhandenen Daten werden entfernt.
- APPEND: einen Datensatz oder eine Reihe von Datensätzen zur Datenquelle hinzufügen. Existiert die Datenquelle nicht wird sie neu erstellt.
- READY_TO_PROCESS: zeigt das logische Ende des Datenstroms an. An diesem Punkt ist die Datenquelle bereit für die Verwendung und der Import wird durchgeführt.
Data
data muss immer als Array angegeben werden, auch wenn sie nur ein Element enthält. Bei einigen Operationen, wie z.B. CLEAR, ist data
optional, bei Verwendung wird die Datenquellen erst geleert und dann mit den Daten gefüllt.
Das Format der Daten ist nicht vordefiniert und hängt vom Kunden ab. Eine wichtige Einschränkung von Chioro ist jedoch, dass, sobald ein bestimmtes Attribut in einem bestimmten Format übertragen wird, alle nachfolgenden Zeilen dieses Format respektieren müssen und Daten nur in diesem Format senden. Wenn zum Beispiel das Attribut “Farbe” als Zeichenkette “rot” gesendet wird, darf keine andere Zeile das dasselbe Attribut “Farbe” mit einem verschachtelten Format wie {“Farbton” : 12, “Sättigung”: “22”, …}. “Farbe” darf also nicht einmal als einfacher String erscheinen und ein andermal als Array.
Response
Im Idealfall gibt der Vorgang eine leere Liste zurück, wenn alles erfolgreich importiert werden konnte. Wenn eine der Zeilen einen Fehler verursacht wird er in der Response-Liste angezeigt.
BMEcat Feature
Es besteht nun die Möglichkeit eine sogenannte Whitelist in die Datenquelle einzubinden wenn man “BMEcat” als Datentyp ausgewählt hat.
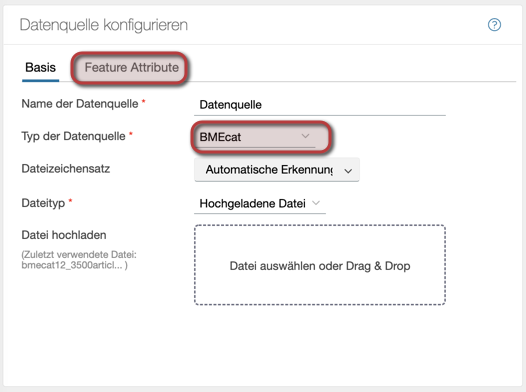
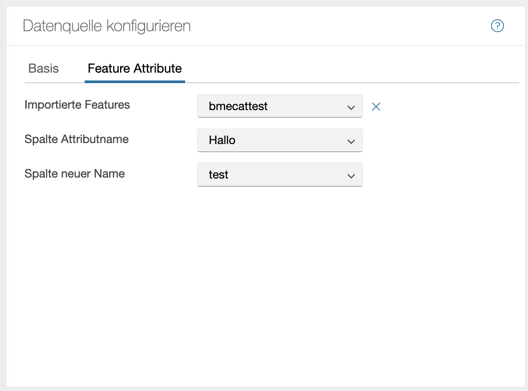
Mit dieser Whitelist gibt man die Attribute an die nur angezeigt werden dürfen.
Bleibt das Feld “Importierte Features” leer werden alle Feature-Attribute aus dem XML importiert. Es besteht hier die Möglichkeit die beiden Felder “Spalte Attributname” und “Spalte neuer Name” leer zu lassen. Falls dies der Fall ist, bleibt die alte Logik vorerst erhalten und nur die Features die in der Tabelle vorhanden sind werden importiert. Vorrausgesetzt die Datentabelle besitzt nur eine Spalte. Falls diese 2 Spalten besitzt wird als Default die erste genommen.
Wenn das Feld “Spalte neuer Name” befüllt ist, vorrausgesetzt die Datentabelle besitzt mindestens 2 Spalten, werden die Attribute die in “Spalte Attributnamen” gesucht. Falls diese gefunden werden, werden sie mit dem neuem Namen der in der Datentabelle steht, ersetzt.