In der Aggregation können Daten auf verschiedene Arten zusammengefasst werden. Dieses Zusammenziehen findet innerhalb der Tabelle statt.
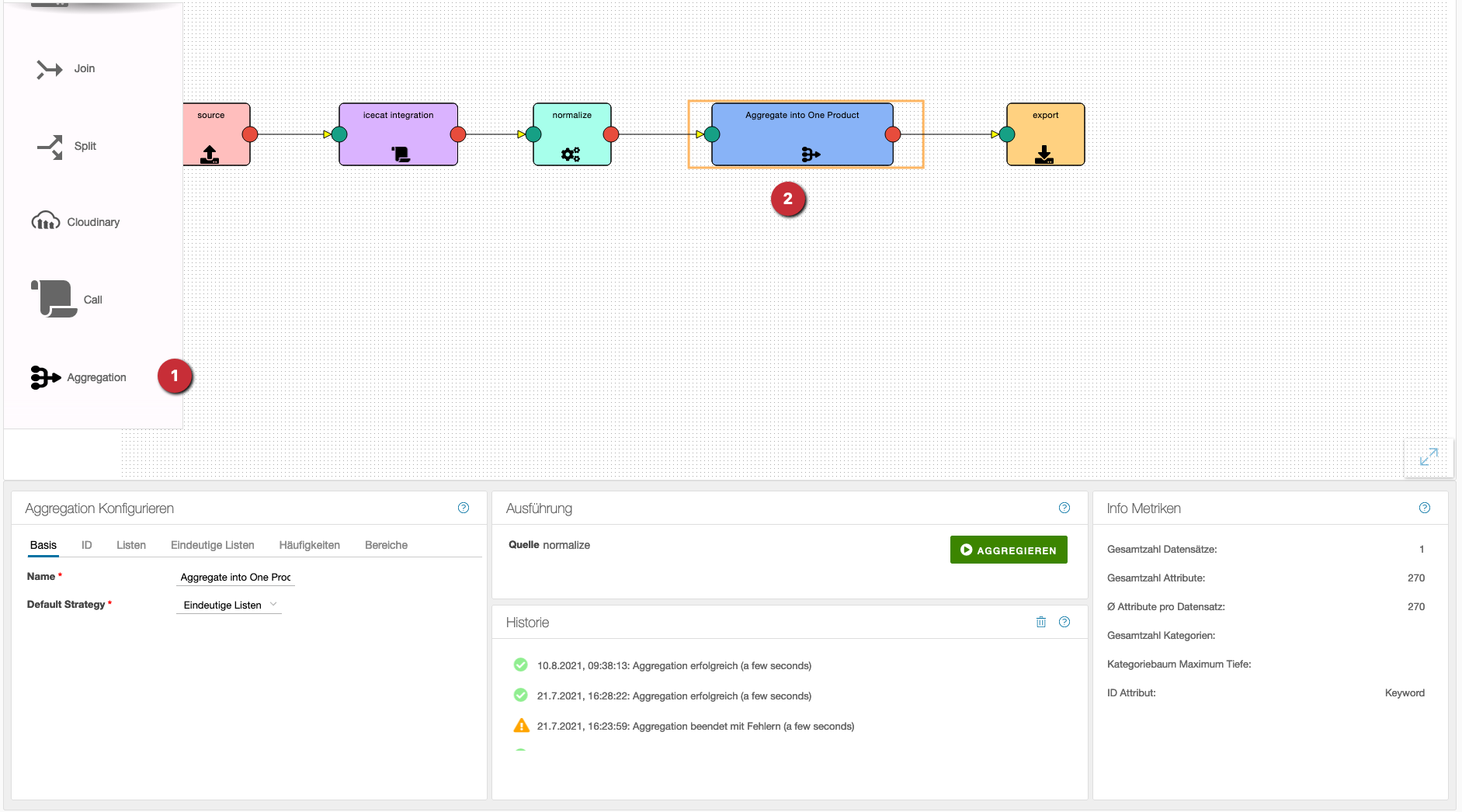
- Wie gewohnt lässt sich die Operation aus der linken Spalte auf die Arbeitsfläche ziehen.
- Danach wird die Aggregation mit den gewünschten Flowelementen verbunden.
Um die Aggregation zu konfigurieren sind 6 Tabs vorhanden:
Basis
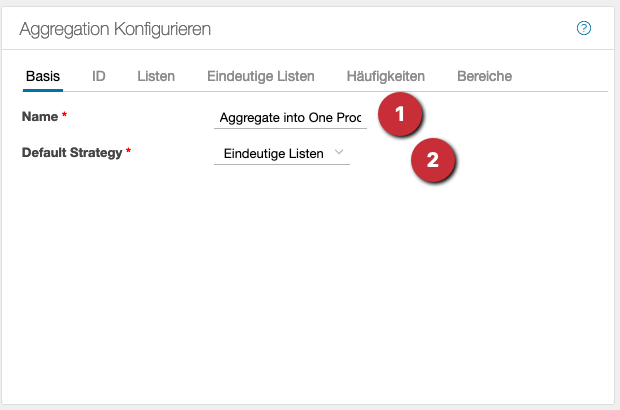
- Ein aussagekräftiger Name für die Aggregation sollte vergeben werden
- Bei ‘Default Strategy’ sind folgende Einstellungen möglich: ⋅⋅* Listen, hier werden alle Daten ohne Änderung zusammengefasst ⋅⋅* Eindeutige Listen, hier werden die Daten einmalig übernommen, doppelte nicht berücksichtigt ⋅⋅* Häufigkeiten verhalten sich wie eindeutige Listen, zusätzlich wird die Häufigkeit des Vorkommens hinzugefügt Die Einstellungen in diesem Tab gelten für die ganze Operation.
ID
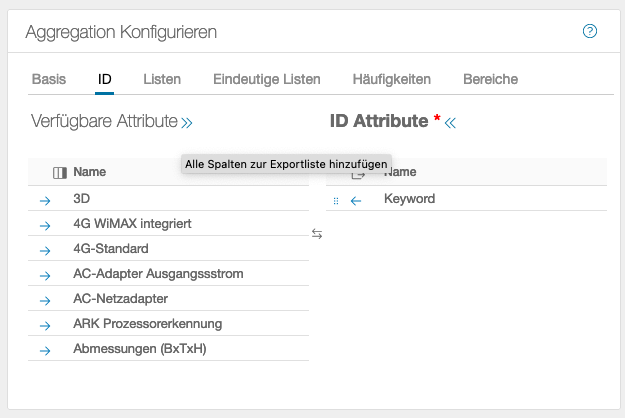
Damit wird ein Attribut zur ID erklärt. Es muss mindestens ein ID-Attribut vorhanden sein
Listen
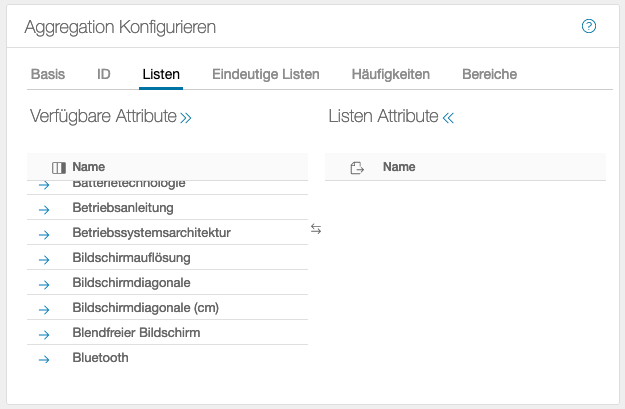
Die Daten werden ohne Änderung zusammengefasst.
Eindeutige Listen
Hier werden die Daten einmalig übernommen, und doppelte nicht berücksichtigt. Um die Anzahl der Dopplungen zu ermitteln wird der Tab Häufigkeiten verwendet.
Häufigkeiten
Im Beispiel werden die Häufigkeiten der Attribute RAM, 4G und Typ zurückgegeben, d.h. die Daten werden einmalig übernommen, bei einem weiteren Auftreten die Häufigkeit hochgezählt.
Bereiche
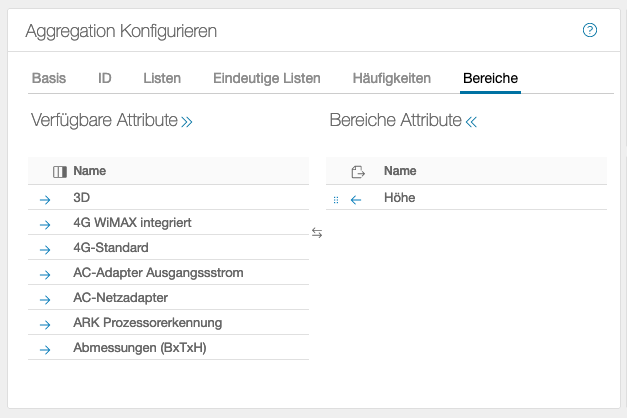
In diesem Beispiel wird die Spalte Höhe ausgewertet. Als Ergebnis werden die minimale und maximale Höhe zurückgegeben. Der Tab Bereiche lässt sich nur auf numerische Daten verwenden, alle anderen Werte führen zum Fehler.